Содержание
Чтобы уменьшить нагрузку на существующие традиционные серверы FTP и HTTP и ведущие к ним каналы, распределив её между всеми участниками сети.
Файлообменные сети используют свой собственный набор протоколов и программного обеспечения, несовместимый с FTP/HTTP и обладающий важными усовершенствованиями.
Первое отличие заключается в роли клиента: каждый клиент не только скачивает данные, но и позволяет подключаться к нему другим клиентам, чтобы скачивать от него те файлы, которые он скачал у других, и те, которые он публикует сам.
Второе отличие заключается в роли сервера: FTP- и HTTP-сервер просто хранят и передают данные клиентам. В файлообменной сети задача сервера (если его наличие вообще предусматривается конкретным протоколом) сводится не только и не столько к хранению и передаче данных, сколько к координации клиентов:
- какой IP-адрес какому клиенту принадлежит;
- у какого клиента какие файлы имеются;
- какие фрагменты каких файлов где находятся;
- кто сколько скачал к себе;
- кто сколько дал скачать от себя другим.
Таким образом, в файлобменной сети присутствуют программы не двух, а трёх типов:
- клиент-паразит, который только скачивает;
- клиент-водовоз, который и скачивает, и отдаёт;
- сервер-координатор (он же отдаёт файлы клиентам, которые обращаются за ними первыми).
При этом в одной программе может быть совмещено несколько функций.
Как происходит работа в типичной файлообменной сети?
- сервер, отдавая клиенту файл, запоминает IP-адрес клиента и имя файла;
- если клиент запрашивает у сервера файл, уже имеющийся у других клиентов, сервер указывает ему IP-адреса этих клиентов;
- клиенты информируют сервер обо всех клиентах, которые к ним подключаются, и файлах, которые те запрашивают;
- если файл имеется на нескольких узлах, клиент будет скачивать с каждого из них непересекающиеся блоки файла, пока не получит весь файл целиком.
Клиент может быть паразитом вынужденно, если он находится в приватной сети, отделённой от внешнего мира файрволлом и/или NAT'ом, так что снаружи к нему не подсоединиться. Однако даже клиент-паразит всё равно предпочтительнее FTP-клиента благодаря принципу распределения запросов по множеству серверов (т.е., в данном случае - по множеству отдающих клиентов).
Даже если ваша любительская сеть или клиентская сеть Интернет-провайдера закрыты от внешнего доступа, пиринговые системы могут оказаться полезными для передачи данных внутри такой сети. Например - некто с безлимитным тарифом скачивает из Интернета нечто громоздкое, затем остальные абоненты скачивают данные от него (и друг от друга!) через P2P.
Какие достоинства имеет файлообменная сеть?
- так как каждый клиент, который что-то скачал, сам готов отдавать данные другим клиентам, узлов, с которых новые желающие могут получить данные, постепенно становится много;
- принимающий узел получает возможность формировать очереди закачки c отдающих узлов пропорционально скоростям приёма - чем быстрее связь с каким-то из них, тем больше блоков с него будет скачано;
- если один из отдающих узлов выключается, это не приводит к срыву закачки в целом;
- у каждого из отдающих узлов нагрузка на сеть снижается тем сильнее, чем их больше;
- скорость закачки будет ограничиваться (в идеале) только толщиной входного канала принимающего узла, потому что это единственное место, где сводится воедино трафик, поступающий от многих источников.
Благодаря клиентам, которые и принимают, и отдают, файообменные сети принято относить к т.н. одноранговым сетям, или сетям типа peer-to-peer (равный-к-равному, сокращённо P2P). Чем это отличается от архитектуры "клиент-сервер", по которой выполнены протоколы FTP и HTTP?
В сети типа "клиент-сервер" сервер - это компьютер, занимающийся непосредственных хранением и/или обработкой полезных данных: файлов, баз данных и т.д.
В P2P-сети в зависимости от конкретного протокола сервер может не требоваться вообще, требоваться обязательно (как в ICQ) или требоваться опционально (как контроллер домена в сети Microsoft). Но в любом случае, хранением и обработкой собственно данных он не занимается - этим занимаются клиенты, а сервер только управляет их работой, плюс хранит различные служебные данные, необходимые ему для управления.
Например, контроллер домена в сети Microsoft Windows централизованно хранит списки пользователей, а рабочие станции могут напрямую обмениваться друг с другом файлами через сетевые папки (shared folders), которые каждая может как отдавать («расшаривать») в общий доступ, так и подключать из сети; при этом как в правах доступа к папкам, так и в запросах на подключение фигурируют имена пользователей, хранимые и проверяемые контроллером домена.
Служебные данные, предназначенные для обслуживания полезных данных и представляющие смысл только в связи с этим обслуживанием, принято обозначать термином метаданные. Пример: содержимое файла является полезными данными, а его имя, координаты на диске, права доступа, время создания и т.д. - всё это метаданные. Ещё пример: Веб-страницы на HTTP-сервере - это полезные данные, а запись соответствия имени (или имён, как в случае с ya.ru и yandex.ru) HTTP-сервера его IP-адресу (или IP-адресам, как в случае с www.microsoft.com), хранимая на DNS-сервере - это метаданные, необходимые для координации доступа к Веб-страницам.
Естественными врагами файлообменных сетей являются производители любой информации, предназначенной для массовой продажи и представимой в цифровом виде - музыки, фильмов, книг и программного обеспечения, так как пользователи P2P-сети получают возможность бесконтрольно обмениваться всем этим друг с другом, минуя официальных продавцов. Более того, большинство P2P-сетей расчитано в первую очередь именно для этих целей!
Бороться с подобным бедствием юридическими средствами имеет смысл при соблюдении двух условий:
- протокол обмена предусматривает наличие координирующего сервера;
- разработчик протокола либо не распространяет программу-сервер вообще, либо распространяет только за деньги.
В таком случае объектом судебной атаки становятся владельцы серверов, а без них тихо умирает и вся сеть. Во всех остальных вариантах сеть просто не имеет фиксированных точек, ударами по которым её можно было бы парализовать. Поэтому пользователи сравнительно более примитивного однорангового протокола Gnutella могут не опасаться неприятностей, а более совершенный Napster, основатель одноимённой файлообменной сети и фактически первооткрыватель идеи для массового потребителя, был в итоге засужен по инициативе рок-группы «Металлика» Американской Ассоциацией производителей звукозаписей (RIAA). Хронология этих событий увлекательно описана на сайте Грани.ру. Там же находится и подборка цитат от участников противостояния.
Существует и широко практикуется ещё один способ борьбы с пиратством в P2P-сетях, более оперативный и универсальный, но менее надёжный. Он состоит в анонимной публикации собственных материалов со специально внесёнными дефектами: с плохим качеством, в некорректном формате, с отсутствующими фрагментами. При известной энергии краденые оригиналы растворяются в туче легальных подделок, и пользователям оказывается проще обзавестись информацией законным путём, нежели выискивать её через P2P.
Что касается Napster, то его коммерческий успех был обусловлен той же причиной, что и плачевный конец в 2000 году - централизованностью. Благодаря ей Napster теоретически имел возможность продавать:
- ключи регистрации для программы-клиента;
- право поключения к серверу-координатору на определённый период или на количество раз;
- рекламную площадь в программе-клиенте;
- рекламную площадь на Веб-сайте.
Нынешний Napster вместе со сменой владельцев изменил и правила работы:
- программное обеспечение переписано практически полностью;
- доступ к серверу возможен только по подписке;
- количество файлов, загружаемых клиентом за месяц, ограничено;
- пересылка того или иного файла может быть заблокирована по заявлению обладателя прав на оригинал;
- обладатели прав на передаваемые по сети данные получают за это от Napster'a лицензионные отчисления.
Первоначально количество компьютеров было невелико, все они были дорогими и (уступая по мощности даже современным наладонникам) многопользовательскими. Терминальные устройства, за которыми работали пользователи, представляли из себя симбиоз пишущей машинки, телевизора и программируемого микрокалькулятора, и были расчитаны на выполнение одной-единственной задачи - предоставлять интерфейс для обращения к главному компьютеру. Таким образом, с появлением вычислительных сетей вопрос о предоставлении доступа к ресурсам компьютера через сеть зачастую не возникал -- такой доступ был всего лишь развитием уже существующего доступа через физически подключенный терминал.
Свою роль играло и то, что значительная часть компьютерного парка находилась в ведении университетов с их демократичной, даже анархической атмосферой. Это формировало как дисциплину разработки программ-сервисов, так и дисциплину их обслуживания. На каждом компьютере были запущены службы доступа к файлам, обмена новостями и почтой, распознавания сетевых имён, терминального доступа и т.д. Каждая из них была настроена на обслуживание любого желающего в гостевом или транзитном режиме, если соответствующий протокол это позволял. Например, почтовый сервер Санкт-Петербургского Центра суперкомпьютерных приложений вплоть до осени 1998 года работал в режиме open relay, то есть соглашался пересылать по назначению почту, поступающую от произвольных внешних клиентов - прекрасный способ забросать Сеть рекламой и остаться незамеченным.
Другим примером, характеризующим в большей степени стиль разработки, являются первые версии DNS, протокола распознавания сетевых имён. В отличие от нынешнего иерархического режима (сбор и рассылка обновлений осуществляются по цепочке «клиент-провайдер-корневой сервер имён»), первые DNS-серверы обменивались данными напрямую. Хотя такая схема открывала богатые возможности для подтасовок, отказались от неё не из-за проблем с безопасностью, а из-за той перегрузки сети, к которой она приводила.
Суммируя всё вышесказанное, можно сказать, что первоначально Интернет представлял из себя одноранговую сеть, хотя и технически несовершенную, что, впрочем, с учётом её малых тогдашних размеров и профессионализма пользователей было, как правило, некритично.
Бум Интернета является следствием бума персональных компьютеров. В свою очередь, чёткое деление «клиент-сервер», которое существует в Интернете с момента его массового распространения и по сей день, обусловлено следующими свойствами ПК:
- ограниченность аппаратных ресурсов;
- недостаток серверного ПО;
- отсутствие полноценной многозадачности, мешающее запускать сетевые сервисы в фоновом режиме;
- повремённая оплата соединения при работе с Интернетом через модем;
- постоянная смена IP-адреса, зависящая от выбора провайдера, телефонного номера и номера линии в многоканальном соединении;
- дефицит IP-адресов и беззащитность клиентских компьютеров перед атаками из сети заставляла владельцев сетей «прятать» их от доступа извне за прокси-сервер, пакетный фильтр (firewall) и транслятор сетевых адресов (NAT).
Кое-что из перечисленного уже преодолено, кое-что - пока нет. Вследствие этих причин персоналка до поры до времени могла быть в сети только клиентом.
К моменту появления первой получившей признание файлообменной сети Napster положение дел на рынке ПК было следующим:
- персональные компьютеры стали достаточно мощными;
- настольные операционные системы стали многозадачными;
- программы для организации сервера доступны для всех основных ОС;
- на смену коммутируемым подключениям пришли выделенные, в которых и время на линии, и исходящий трафик бесплатны;
- постоянные подключения позволили делать IP-адрес клиента неизменным;
- предстоящее внедрение нового протокола IPv6, в котором под адрес компьютера отводится 128 бит (вместо 32 бит в распространённом сейчас IPv4), позволит провайдерам выдавать клиентам глобально видимые IP-адреса без ограничений;
- появились персональные средства защиты (антивирусные мониторы и пакетные фильтры) способные предохранить ПК от заражений и сетевых атак.
Средний компьютер снова дорос до того, чтобы быть сервером. Но теперь такой компьютер имеется в каждой квартире.
Собственно получению файла предшествуют два действия, поддержке которых в FTP/HTTP достаточного внимания не уделено:
- пользователь выбирает файл на сервере;
- клиентская программа получает от сервера надёжный идентификатор файла, после чего отправляет запросы на файл с данным идентификатором другим клиентам.
Перечислим сведения о файле, которые сервер в принципе может сообщить пользователю, чтобы тот сделал выбор:
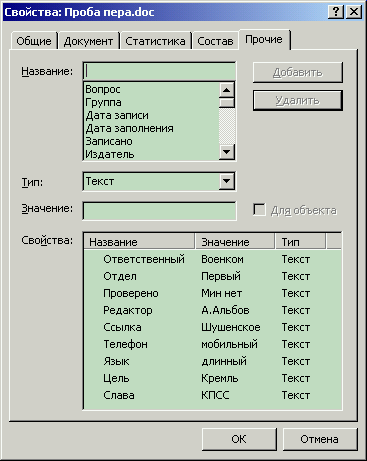
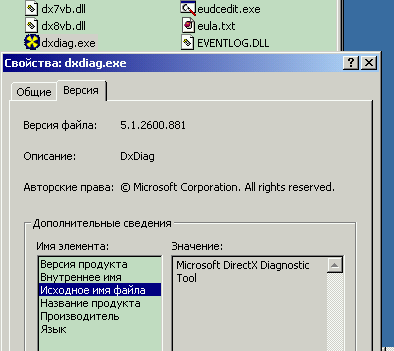
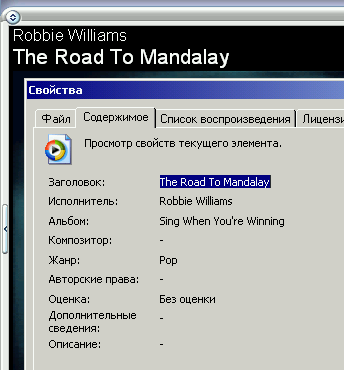
- имя, размер, время создания и прочие метаданные, предоставляемые файловой системой;
- сведения из файлов-описателей, расположенных в том же каталоге (FILE_ID.DIZ, README*, *.LSM, FILES.BBS, DESCRIPT.ION и т.д.);
- если файл хранит текст (DOC, PDF и т.д.), то начальную часть текста;
- если в формате файла предусмотрено место для комментариев (DOC, MP3, EXE, ISO, RPM, ZIP, RAR и т.д.), то содержимое комментариев;
- любые дополнительные описания, которые публикатор решит ввести для файла вручную.
Рисунок 2. Примеры метаинформации, хранимой в файлах разных типов
| ... в документе Microsoft Word (DOC) | ... в исполняемом файле Windows (EXE) | ... в файле звукозаписи (MP3) |
|---|---|---|
 |  |  |
Что является надёжным идентификатором для файла? Во-первых, GUID, т.н. глобально-уникальный идентификатор, автоматически генерируемый и назначаемый файлу в момент публикации. Во-вторых, контрольная сумма, вычисляемая по содержимому файла. Даже если файл будет опубликован независимо несколькими узлами, каждый из которых присвоит ему свой собственный GUID, по контрольной сумме всё равно можно будет понять, что это один и тот же файл. Хотя вычисление контрольных сумм занимает много времени, многие P2P-программы умеют производить его в фоновом режиме.
Привычным способом указания программы, которую мы хотим запустить, является указание её имени в файловой системе, например: C:\WinNT\System32\cmd.exe или \\server\games\tetris\tet.exe.
Протокол HTTP позволяет запускать программы на выполнение другим компьютером, т.е. удалённо (remote). Например, команда http://www.mail.ru/cgi-bin/auth запустит на сервере Mail.ru утилиту авторизации и выведет на ваш экран Веб-страницу, сгенерированную этой утилитой, присланную вам для заполнения и обратной отправки -- с повторным запуском утилиты авторизации на Mail.ru: для проверки введённых вами данных и вывода Веб-страницы с содержимым почтового ящика.
Однако такие символические имена обладают существенным недостатком: они неуникальны. Как, в самом деле, разработчик клиент-серверной системы должен выбирать название для серверного компонента, если присутствует риск, что разработчик другой системы выберет такое же имя для своих собственных нужд? Как администратор сумеет разместить эти две системы на одном сервере?
Такая же проблема существует не только на сетевом, но и на внутримашинном уровне: попытка разработчика приложения искать динамическую библиотеку (DLL) в общесистемном каталоге по имени вполне может привести к тому, что будет по ошибке загружена библиотека с тем же именем, но установленная другим пакетом и хранящая другой набор подпрограмм (с другими или - ещё хуже - совпадающими именами). Этой проблемы можно было бы избежать, будь у библиотек названия вида «фирма_продукт_компонент», но пока названия типа StrUtil, MyUtil или xBase можно встретить гораздо чаще.
Поэтому в протоколах передачи управления и данных через сеть, альтернативных HTTP с надстройкой в виде CGI-BIN, таких как CORBA и Microsoft DCOM, вызов серверного компонента осуществляется не по имени файла, а по GUID. GUID представляет из себя 128-разрядное двоичное число, сгенерированное автоматическим образом на компьютере разработчика из следующих компонентов:
- 48-разрядный адрес сетевой карты;
- текущее время;
- случайный довесок.
Об удобстве читабельности и запоминабельности речь не идёт, потому что GUID никогда не приходится вводить вручную: программа-клиент всегда хранит фиксированный GUID программы-сервера, для взаимодействия с которой она разработана, а при разработке GUID назначается создаваемым компонентам если не автоматически, то через буфер обмена путём Cut'n'Paste.
Возможно, стоит подчеркнуть ещё раз тот факт, что GUID и IP-адрес компьютера - это разные вещи! GUID - это номер (если угодно - адрес) программы внутри компьютера, остающийся неизменным, на каком бы компьютере и в каком каталоге она не была инсталлирована; и в то же время гарантированно не совпадающий с номером любой другой программы. Эти номера позволяют как серверу отличать внутри себя разные программы, так и клиенту - находить разные экземпляры одной программы на разных серверах.
Теоретически алгоритм генерации, принятый сейчас в качестве стандартного, обещает отсутствие случайных совпадений приблизительно до 3400 года. На практике как минимум одно такое совпадение уже было: вкладка свойств видеокарты S3 для Панели управления и один из компонентов переводчика Stylus имели одинаковые GUID.
Соответствие между GUID и именем файла программы, запускаемой по приходящим из сети запросам, хранится где-то в общесистемных настройках, куда заносится при инсталляции программы. Например, в Windows для этого используется ветка реестра HKEY_CLASSES_ROOT\CLSID, а регистрации в ней - утилита RegSvr32. GUID в Windows назначаются не только сетевым сервисам, но и вообще всему, что может быть запущено или загружено, и нуждается в однозначной идентификации: DLL-библиотекам, классам и т.д.
P2P-сеть является полноценной распределённой системой, то есть:
- одни и те же данные резервируются на множестве узлов;
- список узлов формируется и обновляется автоматически;
- у клиента существует возможность так же автоматически выбирать узлы для получения данных;
- при выходе из строя части узлов система остаётся работоспособной.
В то же время, FTP/HTTP используют только ту информацию о файле, которая предоставляется им файловой системой, на которой файл расположен: имя, размер, дата создания и последнего доступа - никакие из этих метаданных не уникальны.
По этой причине ни базовый FTP, ни базовый HTTP распределёнными системами не являются. Один и тот же файл или веб-страница могут иметь на разных узлах разное имя. И наоборот, разные файлы и страницы на разных узлах могут называться одинаково. У клиента нет надёжного способа определить, на каких узлах находятся требуемые данные. И, как уже говорилось, FTP-/HTTP-клиенты по мере получения данных не становятся их распространителями и не разгружают от запросов оригинальный сервер. Конечно, широко практикуется создание т.н. зеркал (mirrors), автоматически синхронизируемых с сайтом-оригиналом, но ручными операциями остаются как создание сайта-зеркала - для администратора, так и выбор ближайшего зеркала - для пользователя.
Оставаясь в рамках FTP/HTTP-протоколов передачи через сеть, наверное, можно было бы добиться близкой к P2P-функциональности внеся следующие дополнения в поведение клиентов и серверов:
- на каждом клиенте в фоновом режиме запускается FTP/HTTP-сервер, чтобы отдавать файлы другим клиентам;
- дополнительная программа, запускаемая на каждом сервере, вычисляет контрольные суммы для публикуемых файлов и записывает их в расположенные рядом служебные файлы-описатели;
- вместе с файлами скачиваются их описатели;
- один или несколько компьютеров выполняют роль поисковых серверов, то есть в качестве клиентов просматривают каталоги всех Веб-серверов и сами, в свою очередь, предоставляют к результатам поиска Веб-интерфейс, удобный для автоматического разбора.
- перед началом закачки клиенты загружают с поисковых серверов базу со сведениями о файлах, в то же время сообщая серверам о своём существовании (посредством записей, остающихся в log-файле сервера, или специальными уведомлениями через CGI-BIN).
Очевидно, что при таких серьёзных усовершенствованиях легче разработать абсолютно новый протокол и программное обеспечение с нуля, нежели цепляться за уже существующие стандарты - что и было сделано Napster'ом, а следом за ним и многими другими.
Впрочем, одно применение протоколу HTTP в P2P-сетях всё же нашлось. Дело в том, что встроенные возможности P2P-протоколов не позволяют составлять полную базу поиска файлов, не перегружая сеть (та же проблема, что и в ранних версиях DNS). Желательно наличие выделенных компьютеров, которые будут вести список известных P2P-серверов, просматривать их в качестве клиентов, дублировать у себя полученную информацию и предоставлять её настоящим клиентам, не беря на себя координирующих функций. Такое предоставление сведений может осуществляться как через P2P-протокол, так и через обычный Веб-интерфейс. Например, сайт www.filedonkey.com является Веб-интерфейсом поисковой системы по серверам EDonkey2000. Точно так же, кстати, работает поисковая служба FileSearch.ru, но применительно к протоколу FTP: в качестве FTP-клиента обшаривает сеть, сохраняет у себя метаданные файлов и обслуживает запросы пользователей через Веб-интерфейс с CGI-сценариями. Некоторые универсальные поисковые системы, например, FileWatcher, в дополнение к поиску по FTP ввели у себя поиск по P2P.
Описание конкретных протоколов и программ будет темой отдельной статьи. Размер одной публикации не позволяет уместить его вместе с общими сведениями. Тем не менее, можно сформулировать несколько вопросов, путём поиска ответов на которые получится самостоятельно составить мнение о том, что скрывается за тем или иным термином.
Услышав термин, в первую очередь необходимо понять, названием чего он служит: протокола или программы? Один и тот же протокол может поддерживаться несколькими программами. Например, HTTP-протокол поддерживается серверами Apache и MS IIS, а также клиентами Mozilla, Internet Explorer, Opera и т.д.; P2P-протокол под названием EDonkey2000 поддерживается одноимённой программой, а также программами eMule, Shareaza и т.д.
В то же время одна программа может поддерживать несколько протоколов. Например, большинство Веб-клиентов (Веб-браузеров) поддерживает протоколы HTTP и FTP, а P2P-клиент Shareaza поддерживает P2P-протоколы EDonkey2000, BitTorrent и Gnutella2.
Если речь идёт о протоколе, то интересуйтесь следующими аспектами:
- Требуется ли отдельный сервер-координатор?
- Какие программы-клиенты его поддерживают?
- Насколько широко клиенты и серверы данного протокола распространены в Интернете?
- Для передачи какой информации (мультимедиа, ISO-образы и т.д.) в первую очередь разрабатывался протокол и поддерживающие его программы?
- Развитием какого протокола является данный протокол, и в какой мере они совместимы?
- Существует ли открытое описание либо лицензирование протокола (следствием чего будет более широкий выбор программ)?
- Если протокол закрыт и требуется отдельная программа-сервер, то можно ли подключаться к узлам-серверам бесплатно? Можно ли её скачать для использования в приватной сети?
Применительно к программе важны ответы на следующие вопросы:
- Какие протоколы она поддерживает?
- Насколько она бесплатна (shareware, adware, open source)?
- На какие платформы она перенесена (windows, linux)?
Ответам на эти вопросы по отношению к наиболее популярным протоколам и программам P2P будет посвящена следущая часть статьи.